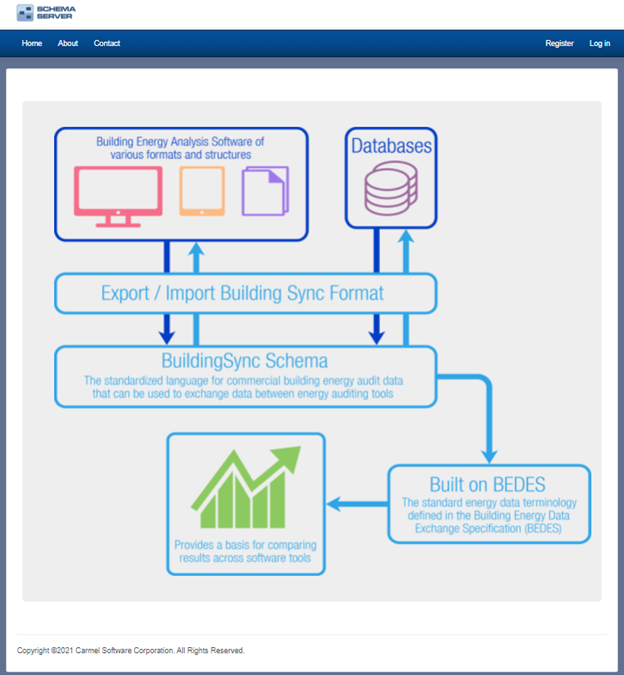
BuildingSync is a schema developed by the National Renewable Energy Lab (NREL) that provides a standardized data format for describing the physical and operational characteristics of buildings specifically for the purpose of commercial energy audits. This schema can be exported and imported by many software tools that allow common information to be shared (ie – interoperability). For a list of use cases, click here.
The BuildingSync Schematron tool includes a set of rules that validate data against the BuildingSync schema, helping to ensure that data is consistent and accurate for any specific software tool. In this case, a Schematron file was created solely for validating BuildingSync into ASHRAE BEQ portal.
ASHRAE Building EQ is a web-based tool developed by the American Society of Heating, Refrigerating, and Air-Conditioning Engineers (ASHRAE) that helps building owners and operators evaluate the energy performance of their buildings. The tool allows users to compare their building’s energy use to similar type buildings in the same climate zone and identify areas where energy efficiency improvements can be made. Building EQ includes a set of energy performance metrics that can be used to track improvements over time.
Users can import BuildingSync files into existing ASHRAE Building EQ projects allowing them to pre-populate the project with common energy auditing data.
We at Carmelsoft often get asked the some questions over and over again about Green Building XML (gbXML) since we oversee this popular BIM/energy modeling schema. So, we typed some of these FAQs into the ChatGPT generative AI engine, and it surprisingly returned some accurate and easy-to-understand results for a relatively obscure topic such as gbXML and energy modeling. We edited it a bit for clarity and expanded on some of the definitions:
Question 1: What is the difference between the “shell geometry”, “planar geometry”, and “rectangular geometry” elements?
In gbXML (Green Building XML) format, the ShellGeometry, PlanarGeometry, and RectangularGeometry elements are used to define the geometry of building surfaces in a building model. Here’s what each element means:
ShellGeometry: This element defines a building surface as a closed, planar, and non-intersecting 3D geometry. It can be used to represent complex shapes such as curved walls, domes, or vaults. The ShellGeometry element is typically used for building envelopes, such as walls, roofs, and floors.
PlanarGeometry: This element defines a building surface as a flat, planar, and non-intersecting 3D geometry. It can be used to represent flat surfaces such as windows, doors, and glazing. The PlanarGeometry element is typically used for non-enveloping surfaces that have openings, such as windows or doors.
RectangularGeometry: This element defines a building surface as a rectangular, planar, and non-intersecting 3D geometry. It can be used to represent surfaces that are rectangular in shape, such as a simple flat wall. The RectangularGeometry element is typically used for simpler, regular building shapes.
In summary, the difference between these elements lies in the shape and complexity of the building surfaces they define. The ShellGeometry is used for complex and irregular shapes, PlanarGeometry is used for flat surfaces with openings, and RectangularGeometry is used for simple and regular shapes.
gbXML Viewer
In regards to the online gbXML Viewer (aka – Ladybug Tools Spider Viewer), the following elements are used:
Shell Geometry: ShellGeometry data appears to have been used in older vesrions of Spider gbXML Viewer (R2) to gather surface data, and it occasionally appears in other “sandbox” files. Still, it has not been exposed to the user regularly.
Planar Geometry: PlanarGeometry data is used to gather all the coordinates in all the PolyLoops in every Surface. This data is used to draw the surfaces and openings in the gbXML Viewer.
RectangularGeometry: A popup box displays:
All the attributes of the RectangularGeometry of the currently selected surface
All the attributes of the RectangularGeometry of all the openings in the currently selected surface
Question 2: What are the differences between gbXML and Industry Foundation Classes (IFCs)?
Industry Foundation Classes (IFC) and gbXML are both data exchange schemas used in the architecture, engineering, and construction industry to represent building information in a structured and machine-readable format. However, there are some differences between these two standards:
Object-Oriented vs. XML-based: IFC is an object-oriented data model based on the ISO 10303 standard (also known as STEP), while gbXML is an XML-based format. This means that IFC uses a set of pre-defined objects with specific properties and behaviors, while gbXML uses a set of XML elements to represent building information.
Level of Detail: IFC is designed to represent detailed information about building elements, including their geometric, spatial, and semantic properties, which makes it suitable for use in advanced building design and construction processes such as Building Information Modeling (BIM). On the other hand, gbXML is designed to represent simpler building information, such as building geometry and thermal properties, making it more suitable for energy modeling and analysis.
Industry Adoption: IFC is widely adopted by the AEC industry as an open standard for BIM data exchange, and is supported by most major software vendors. gbXML is also widely used, but is more limited in its scope and is primarily used for energy analysis and simulation.
In summary, IFC and gbXML are both schemas used in the AEC industry for building data exchange, but they differ in their data models, level of detail, and industry adoption. IFC is more comprehensive and suitable for advanced building design and construction processes, while gbXML is more focused on energy modeling and analysis.
Also, IFCs are an ISO standard while gbXML is more a consensus standard.
Question 3: What are second-level space boundaries as it relates to energy modeling?
In the context of building design and modeling, a 2nd level space boundary (also known as a secondary space boundary) refers to a virtual boundary that separates two adjacent spaces within a building. Specifically, it defines the boundary between a space and any other adjacent spaces that are not primary enclosed spaces (i.e., spaces that have a direct contact with the outdoors or are conditioned spaces, such as rooms or corridors).
The concept of a 2nd level space boundary is important for several reasons. First, it allows building designers and engineers to more accurately model the thermal performance of a building by accounting for the heat transfer between adjacent spaces that may not have direct exposure to the outdoors. Second, it helps to define the occupancy and use of different spaces within a building, which is important for code compliance and building operation.
In a building model, a 2nd level space boundary can be defined using various methods, such as by explicitly drawing the boundary in a building design software, or by defining a set of rules that define the relationship between different spaces based on their location, orientation, and other properties. The resulting building model can then be used for various purposes, such as energy simulation, code compliance analysis, and facility management.
In June of 2020, Carmel Software received a U.S. Department of Energy Small Business Innovation Research (SBIR) grant to develop a new software tool to help energy modelers and energy auditors better design and maintain energy efficient buildings. The details of that grant were detailed in a prior blog post. This blog post will detail the progress that we have made so far. First, we need to restate the problem that has become even more urgent since last year:
As part of its national infrastructure plan, the Biden Administration has set a goal to retrofit 2 million commercial and residential buildings over the next 4 years. Energy usage and energy auditing data for these buildings need to be stored in a consistent manner to help achieve this aggressive goal.
Simulating the energy usage of buildings using sophisticated software has become a key strategy in designing high performance buildings that can better meet the needs of society. Automated exchange of data between the architect’s software design tools and the energy consultant’s simulation software tools is an important part of the current and future building design process.
In the Phase I funding opportunity announcement (ie – request for proposal or “FOA”), the DOE’s Building Technology Office (BTO) was asking that bidders suggest new workflows for either BuildingSync or HPXML, which are schema “languages” that allow for the transfer of commercial and residential energy auditing information, respectively . Our proposal focused on BuildingSync XML since we are more focused on the commercial building market. Phase I of this proposal focused on the workflow that involves the U.S. Department of Energy’s Asset Score Audit Template to BuildingSync to the ASHRAE Building EQ benchmarking portal. Carmel Software successfully developed a beta of Schema Server that streamlines the flow of information from DOE’s Asset Score Audit Template into ASHRAE Building EQ. With the simple click of a button, the producing or consuming tool performs quick data checks, tests-case validations, and then transfers to the consuming tool (in this case, ASHRAE Building EQ). We also integrated a gbXML viewer and validator so that any accompanying gbXML file for the same building as the BuildingSync XML file could be validated and viewed (assuming it includes the building’s 3D geometry designed from a tool like Autodesk Revit). We also went a bit beyond the scope of the original proposal and added the following features based upon user feedback:
We incorporated building data from additional data sources, most importantly from Energy Star Portfolio Manager. We are now able to import monthly and yearly building utility data (for electricity, natural gas, and other fuel types). This data is used by ASHRAE Building EQ to calculate the Building EQ Score. We do this by integrating with the Energy Star PM API (application programming interface).
We talked with many energy auditors and all of them use Excel to tabulate data and create reports. We created an integration with Microsoft Office software including Word and Excel. This integration allows users to create customized Office templates with keycodes representing data types from the BuildingSync XML data schema. This, in turn, will populate these customized Office templates with actual data from the BuildingSync XML files. The benefit of this is it allows users to keep their custom reporting Excel templates and populate them with data imported by Schema Server.
When we presented the Phase I beta to our DOE program manager and other interested parties, they were quite pleased with the progress that we have made so far. Most importantly, we began validating the true purpose and use of this portal by talking with 50 stakeholders over a 6-month period. The following objectives were outlined in Phase I and were met (or will be met by the end of the Phase I time-period of May 31, 2021):
Objective 1: RPI identified 10+ candidate test cases by interviewing energy modeling practitioners and other related professionals to identify issues with the current building asset data to consuming software tool workflow.
Objective 2: Selected the seven (7) or so most important test cases.
Objective 3: Developed the Schema Server web portal that included the functionality described above.
Objective 4: Developed an application programming interface (API) that allows third-party software developers to integrate with the Schema. This currently only works with Audit Template and Building EQ but will be expanded during Phase II.
We developed Schema Server (https://www.schemaserver.com) which incorporates many of the objectives listed above. This website allows users to create an account, add projects, import BuildingSync XML schemas from Audit Template, validate those schemas, export to ASHRAE Building EQ. It even allows you to store multiple versions of the BuildingSync XML file so it simulates a sort of version control software.
Let’s look at some of the functionality of this website. You are able to create a free account that allows you to begin entering as many projects as you want. A “project” is usually a building.
You can enter the following information about a building including basic demographic information:
We’ll discuss the Energy Star options later. At the bottom of this page is the “Schema Version List”. This is a list of all of the schema file uploads for this particular project. Think of it as almost a version control list similar to GitHub where it includes a list of all of the changes made on one or more files. This Schema Version List is a list of all of the changes that you have made to a schema file (either Building Sync XML or gbXML or others in the future).
As the user adds new schemas to the list, the version number automatically increases. When the user clicks one of the rows, it directs the user to a new web page that appears as follows:
Clicking the Validate button performs validation on the BuildingSync file using what is called Schematron. Schematron is used for business rules validation, general validation, quality control, and quality assurance that is that allows users to develop software-specific validation modules. The SchemaServer Schematron produces a report listing mandatory fields that are missing and a list of generic errors in relation to the imported BuildingSync file. The screenshot below shows an example of this:
The View button takes the user to a new webpage that allows the user to view the XML file in different ways:
I’ve been studying blockchain via an online Udacity course. It’s nothing short of revolutionary. When people say blockchain, most people think of Bitcoin, the popular cryptocurrency that has real value. However, blockchain is more than just cryptocurrency. It’s an entire platform that allows users to develop all new software tools not even remotely related to what exists today. I hope that this blog posting gives you a basic understanding of what exactly blockchain is and how it can be applied to industries such as Heating, Ventilation, and Air-Conditioning (HVAC) and the built environment.
Think of the blockchain as a type of shared database that differs from a typical database in the way that it stores information: typical databases are usually hosted on a company’s server (or user’s cloud account) and is managed and owned by that user. Blockchains store data in blocks that are then linked together via cryptography, and they are 100% public. Most importantly, they can be downloaded by anyone (which I’ve done to my computer). The Bitcoin blockchain stores every single Bitcoin transaction ever completed since 2009. Amazingly, all the user information associated with the Bitcoin transaction stored on the blockchain is anonymous, so they cannot be traced back to individual users (most of the time).
Here’s a good (but busy) graphic that shows an entire Bitcoin transaction on the blockchain:
Another way to look at blockchain is that it is a back-linked, decentralized and distributed-database of encrypted records. Let me simplify this definition a bit:
It’s a data structure where each block is linked to another block in a time-stamped chronological order
It’s an append-only transactional database, not a replacement to the conventional databases
Every node keeps a copy of all the transactions happened in the past which are secured cryptographically. Hence, almost impossible to hack.
All information once stored on the ledger is verifiable and auditable but not editable
Highly fault tolerant as there is no single-point-of-failure
Decentralized blockchains are immutable, which means that the data entered is irreversible and cannot be changed
Ethereum
While the blockchain for Bitcoin solely keeps track of every single Bitcoin transaction that has ever occurred since 2009, there are many other blockchains that focus on other domains. One popular example is Ethereum. Ethereum is a cryptocurrency with real value like Bitcoin. However, it is also a blockchain “virtual machine” that runs “smart contracts”. Smart contracts are simple software programs hosted by the Ethereum blockchain that can perform any number of functions. These simple software programs are programmed in a software language called “Solidity”. A good analogy to smart contracts is the Internet and websites. The Ethereum blockchain is the “Internet” and smart contracts are “websites” that are enabled by the Internet.
The Ethereum blockchain has millions of transactions. These transactions are grouped into “blocks.” A block contains a series of transactions, and each block is chained together with its previous block. Think of it as an encrypted linked list. That’s why it is called “blockchain”.
To cause a transition from one state to the next, a transaction must be valid. For a transaction to be considered valid, it must go through a validation process known as mining. Mining is when a group of nodes, or computers, create a block of valid transactions.
For a block to be added to the Ethereum blockchain, the miner must prove that it is faster than other competitor miners. The process of validating each block by having a miner provide a mathematical proof is known as a “proof of work.”
Any node on the network that is a miner can attempt to create and validate a block. Many miners from around the world try to create and validate blocks at the same time. Each miner provides a mathematical proof when submitting a block to the blockchain, and this proof acts as a guarantee: if the proof exists, the block must be valid.
A miner who validates a new block is rewarded for doing this work. Therefore, it costs Ether (or cryptocurrency) any time a new transaction is created on the Ethereum blockchain. The name of this compensation is called “gas”. Gas is the unit used to measure the fees required for a transaction. Gas price is the amount of Ether you are willing to spend on every unit of gas. It is measured in “Wei.” “Wei” is the smallest unit of Ether, where 1⁰¹⁸ Wei represents 1 Ether.
Ethereum blockchain is also cryptographically secure with a shared state. This means the following:
Cryptographically securemeans that the creation of digital currency is secured by complex mathematical algorithms that are very hard to break.
Shared-state means that the state stored on the blockchain is shared and open to everyone.
Smart contracts provide the following benefits:
Transparency: Allows users to have more confidence in goods purchased. It forces companies to make decisions that favor the consumer.
Traceability: Follows where it came from
Efficiency: Automates some types of transactions and handles back and forth that companies may normally go through. Also, give companies access to a shared database to help verify accuracy of records.
As I mentioned before, what’s unique about Ethereum is that it allows for smart contracts. These are software programs (written in a software language called Solidity) committed to the blockchain where the code and conditions in the contract are publicly available on the ledger. When an event outlined in the contract is triggered, like an expiration date, the code executes. The great thing about the blockchain is that every transaction gets updated on every node that hosts the blockchain, so it keeps everyone involved with the contract accountable for their actions. It takes away bad behavior by making every action taken visible to the entire network.
So, what are use cases for blockchain above and beyond just developing a website to perform that same functionality? The most obvious use case is cryptocurrencies: allowing anyone to download the entire blockchain and view all cryptocurrency transactions.
However, there are many other use cases other than those dealing with cryptocurrencies: basically, anything that requires public validation and exposure, like real estate transactions, intellectual property, voting, supply chain, and associated societal transactions.
Let’s look at a supply chain example: coffee production. There are many actors and actions that take place in the lifecycle of coffee production and consumption. The following image is a unified model language (UML) diagram that illustrates the actors and actions that take place.
Example of 4 actors in a coffee supply chain are:
Farmer: The Farmer can harvest coffee beans, process coffee beans, pack coffee palettes, add coffee palettes, ship coffee palettes, and track authenticity.
Distributor: The Distributor can buy coffee palettes and track authenticity.
Retailer: The Retailer can receive coffee palettes and track authenticity.
Consumer: The Consumer can buy coffee palettes and track authenticity.
Below is a UML sequence diagram that shows the actions between the various stakeholders:
The blockchain is a good mechanism to keep track of the life cycle of the coffee bean, especially for those consumers that want to know where it was sourced from and what the journey was all the way to their cup of coffee.
Solidity
Below is a screenshot of the solidity code in Visual Studio Code that helps keep track of the entire coffee bean life cycle.
The above screen shot shows blockchain source code written in the Solidity programming language specific to developing Ethereum smart contracts. It is an object-oriented, high-level language for implementing smart contracts. It is influenced by C++, Python and JavaScript, and is designed to target the Ethereum Virtual Machine (EVM). Solidity is statically typed, supports inheritance, libraries and complex user-defined types, among other features.
Solidity also focuses a lot on security (for obvious reasons). Because the blockchain is “public”, security is of the utmost importance. Solidity has unique ways to enforce security that differ from other software development languages. For example, directly in the declaration of a function, you can place what are called “modifiers” which are basically inline validators that either allow or disallow the function call based on who is calling the function.
Non-Fungible Tokens (NFTs)
There’s been a lot of talk about non-fungible tokens (NFTs). Non-fungible tokens or NFTs are cryptographic assets on a blockchain with unique identification codes and metadata that distinguish them from each other. They cannot be traded or exchanged at equivalency. This differs from fungible tokens like Bitcoin and Ethereum, which are identical to one other and, therefore, can be used as a medium for commercial transactions.
Basically, NFTs are a way to make digital assets like images, videos, and documents unique using the blockchain. A good real-world example is to compare it to the Mona Lisa painting in the Louvre. There’s only one Mona Lisa painting in the world, and it’s priceless. However, there are many reprints that anyone can buy. The same applies to digital assets. If an artist creates a beautiful JPEG image, they could technically email it to someone then that person could email it to all their friends and now everyone has a copy of that JPEG. However, NTFs allow an artist to ensure that the JPEG painting they created is unique and can then sell it. Even though copies of it could be made, there’s only 1 original that has true value.
Much of the current market for NFTs is centered around collectibles, such as digital artwork, sports cards, and rarities. One example of a use case is to mint NFTs that represent real estate deeds. The NFT would exist on the blockchain while the real estate deed would exist on a file service such as IPFS (inter-planetary file service) which is a shared-file service where encrypted files can be stored.
Interplanetary File Service
Like any widely used service, tokens are now based upon standards. NFTs evolved from the ERC-721 standard. Fungible tokens are based on the ERC-20 smart contract. ERC-721 defines the minimum interface – ownership details, security, and metadata – required for exchange and distribution of gaming tokens.
Applicability to HVAC
The question for this audience is: how can the HVAC industry take advantage of the blockchain to solve existing problems and pain points?
As I mentioned above, the blockchain is good for anything that is appropriate for public accountability. One important HVAC-related topic that is ripe for public accountability is the whole issue around the phase-down of high-GWP (Global Warming Potential) refrigerants (CFCs, HCFCs, and HFCs). EPA regulations under Title VI of the Clean Air Act (CAA) are designed to protect the environment and to provide for a smooth transition away from ozone-depleting refrigerants (ODRs).
EPA regulations under Section 608 of the Clean Air Act include record keeping and reporting requirements that are specific to different professionals or companies involved with stationary refrigeration and air-conditioning equipment. Technicians must keep a copy of their proof of certification at their place of business. Technicians servicing appliances that contain 50 or more pounds of ozone-depleting refrigerant must provide the owner with an invoice that indicates the amount of refrigerant added to the appliance. The records primarily include: location and date of recovery, type of refrigerant recovered, monthly totals of the amounts recovered, and amounts sent for reclamation.
This record keeping is a perfect application for the blockchain. It keeps all stakeholders accountable and also provides interested parties with a verifiable source of information about ozone depleting refrigerant evacuation.
Owners or operators of appliances that contain 50 or more pounds of ODRs must keep servicing records documenting the date and type of service, as well as the quantity of refrigerant added. Owners or operators must also maintain records of leak inspections and tests performed to verify repairs of leaking appliances.
The EPA will also be requiring third-party auditing of business’ HFC record keeping. This will provide transparency of HFC production and consumption data for the general public to view. Stay tuned for more updates on this subject.
Definitions
Like any industry, blockchain has its own expansive vernacular of software and related tool names. Here is just a brief list:
Smart contract: A “smart contract” is simply a software program that runs on the Ethereum blockchain. It’s a collection of code, functions and data that resides at a specific address on the Ethereum blockchain.
DApp: DApp stands for “decentralized application”. It is a piece of software that runs on a distributed or cloud network, rather than on a single dedicated server (like a desktop software program). By distributing the processing power and storage space across many devices, DApps are decentralized, making them more resistant to attack as there is no single point of failure that can be undermined. By their very nature, blockchain smart contracts are DApps.
Truffle: This is a software development environment and a set of software libraries that aid in the development of distributed apps on the Ethereum blockchain. (https://trufflesuite.com/ )
Ganache: This is a local test blockchain desktop (or command-line) application that can be installed on any user’s Windows or MacBook computer. It simulates the actual Ethereum blockchain and allows users to easily test their solidity apps locally on their computer without worrying about the network and consensus delays of the real or testnet Ethereum blockchain. It is an open-source project that is available on GitHub.
Solidity: Solidity is an object-oriented programming language for writing smart contracts. It is used for implementing smart contracts on various blockchain platforms, most notably, Ethereum.
Metamask: This is a cryptocurrency “wallet” and blockchain gateway that is a plugin to a user’s Internet browser. It allows anyone that owns Bitcoin, Ethereum, or another other cryptocurrency to interact with distributed applications that require cryptocurrency. In addition, users can load “test” Ether to test Dapps on the testnets such as Rinkeby and Kopstein. (https://metamask.io/ )
Rinkeby and Kopstein: Rinkeby and Kopstein are Ethereum test networks that allow for blockchain development testing before deployment on the actual Mainnet that costs real money (Ether). (https://rinkeby.etherscan.io/ )
Etherscan: Etherscan is the Ethereum blockchain explorer. It’s basically a search engine for all things Ethereum. It allows users to type in a block hash, a transaction hash, or account id to find out more information about those items. In addition users can search for Ethereum tokens and much more.
Remix: Remix is a web-based integrated development environment that allows users to develop Solidity code, compile it, deploy it to any of local or test Ethereum networks, then interact with the contracts once they are deployed. It’s a great tool for testing and debugging smart contracts and provides a quick user interface so users can input parameters that are sent to the blockchain.
Infura: Infura is a website that is also a web-service API that helps distributed apps connect with the Ethereum blockchain. Infura allows users to connect to the Ethereum blockchain without running a full node. It’s a lightweight alternative to downloading the entire blockchain to a user’s local computer. It makes the connection that allows users to take advantage of the functionality provided by web3.
Web3.js: This is a collection of libraries that allow users to interact with local or remote Ethereum blockchain networks. In other words, it allows developers to create web-based toools that interact with the blockchain.
zkSNARKS: This is a funny-sounding word that is an acronym that stands for: zero-knowledge succinct non-interactive argument of knowledge. That’s quite a mouthful but it’s simply a comprehensive method of data encryption that allows one party to prove it possesses certain information without revealing that information. It involves complex mathematical equations to accomplish this encryption. It is often used on non-fungible tokens (NFTs).
Ethstats: This is a website that keeps track of the status of the Ethereum blockchain and includes tons of statistics on all things Ethereum including latest block #, when the last block was added and much more:
In June of 2020, Carmel Software received a U.S. Department of Energy Small Business Innovation Research (SBIR) grant to develop a new software tool to help energy modelers and energy auditors better design and maintain energy efficient buildings. The details of that grant were detailed in a prior blog post. This blog post will detail the progress that we have made so far. First, we need to restate the problem that has become even more urgent since last year:
As part of its national infrastructure plan, the Biden Administration has set a goal to retrofit 2 million commercial and residential buildings over the next 4 years. Energy usage and energy auditing data for these buildings need to be stored in a consistent manner to help achieve this aggressive goal.
Simulating the energy usage of buildings using sophisticated software has become a key strategy in designing high performance buildings that can better meet the needs of society. Automated exchange of data between the architect’s software design tools and the energy consultant’s simulation software tools is an important part of the current and future building design process.
Steady progress over the past two (2) decades has led to computers having a pervasive impact on the building design industry. Building Information Modeling (BIM) and advances in building energy modeling (BEM) software have resulted in their adoption into the mainstream design process. BIM authoring tools are being adopted by more architects and engineers as these tools improve and become faster and easier to use. The whole premise behind BIM is that it is essentially a “database” where all the building information, including the geometry, is stored.
However, there is a fundamental disconnect between many of the BIM, BEM, building analysis, building asset, and building auditing software tools. Because these tools are developed by 10s, if not 100s, of different software vendors throughout the world, many of these tools do not “talk” with one another despite the fact they many of them require the same information about a building: i.e. – building square footages, wall areas, window areas, occupant densities, plug loads, occupancy schedules, and much more. There are many software tools in the building design, analysis, and auditing industry that allow engineers, architects, and energy modelers to perform the following types of analysis, including whole building energy use, heating and cooling load analysis, lighting analysis, CFD analysis, solar/shading analysis, life-cycle cost analysis, energy benchmarking, energy auditing, and more.
The fact that many of these tools do not talk with one another discourages wide use of these software tools by energy modelers and other related practitioners. This is where “interoperability” comes into play. Interoperability allows for the sharing of data between different software tools developed by many different vendors. Interoperability is essential for BIM to realize its potential as a transforming technology as opposed to 3D CAD programs that are limited in their use as holistic building design tools. In addition to BIM and BEM software, interoperability applies to additional software tools related to building asset information, building audit information, and energy benchmarking. This is where schemas such as gbXML, HPXML, BuildingSync XML, IFCs (Industry Foundation Classes) and others become quite relevant. For example, BuildingSync is a schema developed by the National Renewable Energy Lab (NREL) that allows for the exchange of building energy audit information such as energy efficiency measures, utility data, and building rating information. This information can be used by other types of software tools including energy benchmarking software (such as ASHRAE Building EQ (https://buildingeq.ashrae.org ), energy auditing software such as buildee, and custom software developed by cities and municipalities to satisfy energy auditing rules and mandates. Another example is Green Building XML (gbXML) which is the “language of buildings”. It was developed to facilitate the transfer of building information stored in CAD-based building information models, enabling interoperability between disparate building design and engineering analysis software tools. It is currently supported by over 55 software tools worldwide.
While interoperability schemas have been around for twenty (20) years and are integrated into all major BIM and building performance software tools, end-users still struggle with inefficient and ineffective workflows. For example, geometric information from one BIM authoring tool is not properly represented in a popular HVAC load calculation software tool developed by a third-party vendor. While users can always manually edit and tweak data in an XML file (fortunately, it is clear text) so that it successfully imports into a consuming software tool, the ideal interoperable workflow should not include any type of human intervention. In fact, the ideal workflow would comprise of seamless data transfers between software tools with a simple press of a button. While this may be a utopian vision, there is no reason why the current state-of-the-art cannot be dramatically improved.
In the original Phase I funding opportunity announcement (FOA), DOE’s Building Technologies Office (BTO) requested that research and development be conducted for innovative delivery models for increasing access to building asset data from tools such as Home Energy Score and Asset Score (https://buildingenergyscore.energy.gov/). For Asset Score’s Audit Template tool, one of the ways to increase access to this data by third-party software tools is using an interoperability schema such as NREL’s BuildingSync XML.
BTO asked that bidders suggest new workflows for either BuildingSync or HPXML. Our proposal focused on BuildingSync XML since we wish to target the commercial building space. We suggested developing a comprehensive web-based portal (or Software as a Service, SAAS) that would help facilitate the adoption of BuildingSync and other similar interoperability schemas by third-party building analysis, auditing, and benchmarking software tools. In our 20 years of experience developing and managing the popular Green Building XML (gbXML) schema, we have come to realize that schemas do not work for end users unless there is some type of “transport” mechanism and validator modeler that ensures successful importation into a consuming tool in a straightforward and efficient manner.
As part of Phase I of the FOA, Carmel Software developed a prototype of the SAAS described above, called Schema Server. This tool can import a BuildingSync XML file from any source (including U.S. Department of Energy’s Asset Score Audit Template), perform basic validation using Schematron technology. Additionally, this tool can import additional data for the same building from Energy Star Portfolio Manager and then send it over to a consuming software tool such as ASHRAE Building EQ to receive a building energy benchmarking score. Building EQ assists in the preparation of an ASHRAE Level 1 commercial energy audit (as defined by ASHRAE Standard 211) to identify means to improve a building’s energy performance including low-cost, no-cost energy efficiency measures and an indoor environmental quality survey with recorded measurements to provide additional information to assess a building’s performance.
Also, as part of Phase I of the FOA, we conducted a lot of market research. The reason we were able to do this is we were accepted to DOE’s Energy I-Corps program, a key initiative of the Office of Technology Transitions. This program pairs teams of researchers with industry mentors for an intensive two-month training where the researchers define technology value propositions, conduct customer discovery interviews, and develop viable market pathways for their technologies. Researchers return to the lab with a framework for industry engagement to guide future research and inform a culture of market awareness within the labs. In this way, Energy I-Corps is ensuring our investment in the national labs is maintaining and strengthening U.S. competitiveness long-term.
We found the Energy I-Corps training to be very valuable. It taught us some great concepts such as the Business Model Canvas, the Ecosystem Model, Timeline, Lean Startup Method, and other great concepts. In addition, and most importantly, it held us accountable to conduct 30 interviews within a 6-week period. In fact, we ended up conducting 60 interviews over a 6 month period. As we got better at interviewing, we were able to really target the right stakeholders and get the exact type of information we needed to develop a better software tool.
We recently developed a proposal for Phase II of this FOA that will add much more functionality based upon our interviews with industry stakeholders. The critical need we are focusing on is getting energy auditing and performance data from one software tool to another so that stakeholders are able to do the work accurately and quickly and make better decisions for building energy design and retrofits. For Phase I, we focused on just one workflow for our prototype: Transferring building energy auditing data from Asset Score Audit Template to the ASHRAE Building EQ benchmarking software discussed above. After interviewing the 60 potential stakeholders discussed above, we determined that the above workflow does not satisfy an overwhelming need for most users. However, this software platform (Schema Server) that we created in Phase I will be the basis for Phase II development.
For Phase II, we will be expanding the number of software tools that Schema Server currently focuses on. We will also be combining disparate data about the same building from multiple sources: 3D geometric data about a building may reside in a popular BIM authoring tool while historical electrical utility data may reside in Energy Star Portfolio Manager and energy auditing data may reside in Asset Score Audit Template. There are many other features we will be incorporating that will be discussed in future blogs.
During the downtime due to the pandemic-inspired shelter-in-place in California, I’ve decided to learn some new technologies and concepts related to software design. This has been my first foray into online learning using one of the e-learning platforms. In this case, I signed up for Udacity (https://www.udacity.com).
So far, I’ve been quite impressed. Of course, it does not perfectly substitute live classroom instruction, but it is still quite effective, plus I can skip to the good parts. The course I signed up for is titled “Artificial Intelligence and Python”.
While I’ve programmed scripts with Python before, I never knew that it had some many math and statistic-intensive libraries. Hence, it’s a great language for developing AI-related software since AI is all about statistics: predicting future events based upon historical information.
While the basics of Python programming is not that interesting, the libraries and tools associated with Python are fascinating and actually lots of fun to work with. This blog post will talk a bit about those libraries and also how they apply to AI. As of mid-April 2020, I have not finished the course yet, so emphasis is on the Python libraries used for AI, but not quite AI, itself.
NumPy
NumPy is a library for Python. It is short for “Numerical Python”, and it includes a large amount of functionality related to multi-dimensional arrays and matrices in addition to many mathematical functions. Users can create arrays from Python dictionaries, and then manipulate the arrays in many different ways including reshaping arrays, adding arrays, multiplying arrays, and much much more.
Here’s an example of how a simple numpy array works in Python:
Line 1 imports the numpy library and renames it. Line 2 defines a single row array with values from 0 to 9. Line 3 prints the array and Line 4 displays it.
Line 5 executes the “reshape” function that changes the shape of the array from a single row to a 2×5 array as seen in Line 7. Other functions allow you to insert rows in an array:
8. x = np.insert(x, 1, [10,11,12,13,14], axis=0)
The above “insert” statement inserts a new row at row 1 (row numbers start at 0). The numbers it inserts are: 10,11,12,13,14. The “axis” tells whether to insert a row (0) or column (1).
You can also perform mathematics on 2 arrays including addition, subtraction, multiplication, and division. For example:
x = [[0,1,2,3,4] [5,6,7,8,9]]
y = [[6,3,2,8,7] [1,6,7,3,10]]
print(x + y) = [[6,4,4,11,11] [6,12,14,11,19]]
The above “x” adds each of the elements from each row and column and creates the corresponding matrix with the added values. You can also do the same with the other mathematical functions.
There are many functions associated with numpy that can be found in lots of online documentation.
Pandas
Pandas is another Python library that deals with data analysis and manipulation. It takes the numpy arrays one step further and allow the creation of complex arrays. Let’s look at an example:
Line 1 imports the Pandas library. Line 2 creates a complex matrix where the first column is the index of labels and the 2nd column is the actual data. It looks like this:
eggs
30
apples
6
milk
Yes
bread
No
dtype: object
If you “print groceries[‘eggs’]”. The result is: 30.
Pandas allows you to perform mathematics on values in a matrix:
print(groceries / 2) =
eggs
15
apples
3
milk
Yes
bread
No
You can also create a more complex matrix by creating a dictionary of Pandas series:
You can also create a Python dictionary and then create a Panda dataframe from the dictionary along with indexes. See the following:
#Create a list of Python dictionaries items2 = [{‘bikes’: 21, ‘pants’: 36, ‘watches’: 40}, {‘watches’: 12, ‘glasses’: 51, ‘bikes’: 18, ‘pants’:9}]
#Create a Panda DataFrame store_items = pd.DataFrame(items2, index=[‘store 1’, ‘store 2’])
#Display the DataFrame store_items
It displays as:
bikes
pants
watches
glasses
store 1
20
30
35
NaN
store 2
15
5
10
50.0
To add a column:
store_items[‘shirts’] = [15,2]
Now, the DataFrame displays:
bikes
pants
watches
glasses
shirts
store 1
20
30
35
NaN
15
store 2
15
5
10
50.0
2
Anaconda and Jupyter Notebooks
Now that I have covered a bit of NumPy and Pandas for manipulating data arrays, let’s delve a bit into a Python platform called Anaconda. Anaconda is a “navigator” that allows users to download any and all libraries available for the Python platform. These libraries include mathematical libraries, different types of Python compilers, artificial intelligence libraries (like PyTorch) and the Jupyter Notebook which is a web-based user interface for displaying comments and typing in Python code that runs on command. It’s a tool not necessarily to write production-level Python code, but more a tool to train and test out python code while displaying well-formatted comments.
Below is an example of a Jupyter webpage (or notebook) that includes a comments section with images and then a subsequent code section. This Jupyter notebook talks about Python tensors and Pytorch, the essentials for artificial intelligence.
Neural Networks
Neural networks have been around for a while. The basically emulate the way our brains work. The networks are built from individual parts approximating neurons which are interconnected and are the basis for how the brain learns.
“Digital” neurons are no different. They are interconnected in such a way that over time they learn and are able to apply the learned knowledge to enable useful applications such as natural language (like Alexa) and image identification (like Google Lens). It really is amazing how well it works, and the progress over the past five years alone has been remarkable. I’ll talk more about that later.
So how does it work exactly? Let’s take the example of identifying text in an image; specifically, digits 0 to 9. Just 5 years ago, this was a very complicated problem. Today, it’s a trivial one. The image below displays greyscale handwritten digits where each image is 28×28 pixels.
Greyscale handwritten digits
The first step is to train the software or the “network” in AI lingo. This means feeding it 100s if not 1000s of sample 28×28 pixel images of digits and tagging those images with the actual numbers so the software learns what number the image represents exactly. Luckily, Pytorch includes lots of tagged training data called MNIST. This data can be used to train the network so when you present your own image of a digit, it will correctly interpret what it is.
Single digit
The above image is an example of a greyscale “8” that is 28 x 28 pixels. This is the type of image that would be fed into the network to train it that this type of image is an “8”.
Neural Networks
The above images shows a simple neural network. The far left-hand side displays the inputs (x1 and x2). In our example, the inputs would be the color of each of the 28 x 28 pixels. The values (w1 and w2) are called “weights” These weights are multiplied by each of the corresponding inputs (i.e. – dot product of two vectors) and then inputted into a function that creates an output value (0 to 9) that is compared to the actual value assigned to the image. For example, in the digit training image above (the number “8”), the tag assigned to this image is 8. Therefore, the calculated output is compared to the tagged value. If it matches, then we’ve trained it well for that particular test image and the weights will be reused. If not, then we need to go back and adjust the weights to create a new output value. This back and forth can occur 1000s of times until the correct formula is found.



 FAQs")
 FAQs")
 FAQs")
 FAQs")
 FAQs")
 FAQs")
 FAQs")